

数据库集群如何提高复杂查询性能?
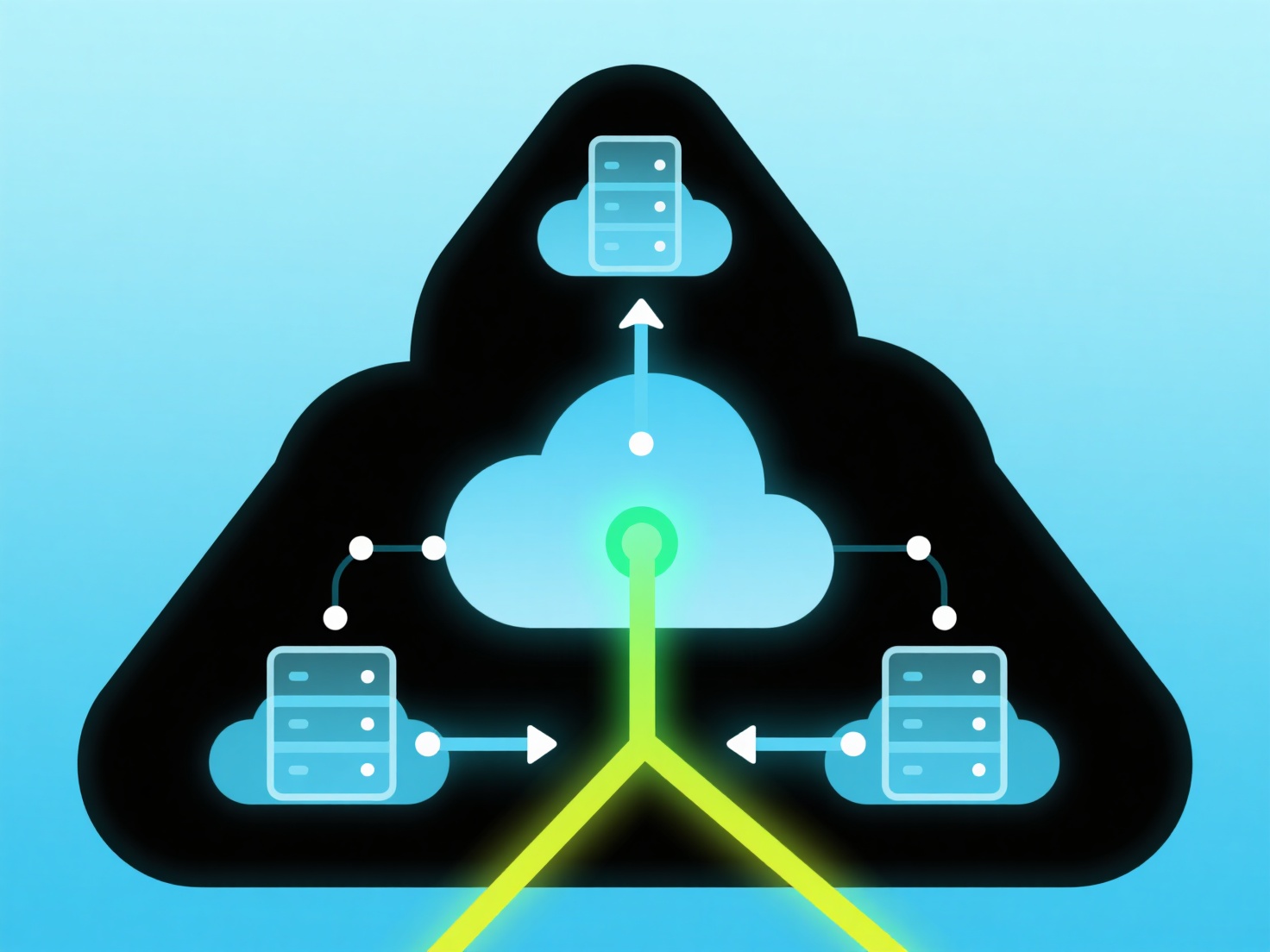
数据库集群将多个数据库服务器组合起来,作为一个单一系统运行。它利用并行处理技术,将复杂查询分解为更小的任务,由各个节点并发处理。这在大规模数据环境(例如OLAP、大数据分析)中至关重要,在这些环境中,单个服务器会成为瓶颈,而集群能显著减少涉及大规模数据集的连接、聚合和扫描等密集型操作的查询响应时间。
核心原理包括数据分区和工作负载分配。分片等技术将数据子集分布到各个节点,实现本地处理。无共享架构确保节点拥有独立的CPU、内存和存储,最大限度减少资源竞争。查询优化器将查询分解为并行子查询,并路由到相关节点。结果随后在中央进行聚合。这种并行性直接提高了吞吐量和可用于复杂查询的计算能力。
实际实施包括搭建无共享集群、战略性地进行数据分区(例如通过分片键)以及配置协调节点。协调节点接收查询、制定并行执行计划、分配任务、管理节点间通信并合并部分结果。这种设置通过添加硬件实现查询性能的近线性扩展,为分析仪表板、报告系统和数据仓库从海量数据中获取更快洞见带来业务价值。
继续阅读
窗口函数如何增强复杂查询的能力?
窗口函数通过允许在定义的行子集上进行特定于行的计算而不合并组,从而增强了复杂查询的能力。这对于分析任务至关重要,例如排名、移动平均值和累积总和,在这些任务中,访问分区内或有序序列中相关行的值至关重要。它们在数据分析、报告和OLAP系统中不可或缺,用于从详细数据中获取洞察,同时保留其粒度。 与使用G...
Read Now →如何在复杂查询中使用LEAD和LAG函数执行基于时间的分析?
LEAD和LAG函数是在`OVER()`子句中用于基于时间分析的窗口函数。它们在按时间等序列排序的结果集中,访问当前行之后(LEAD)或之前(LAG)的行的数据。这些函数对于分析趋势、计算随时间的差异(例如月度环比变化)或无需繁琐自连接即可识别序列至关重要,尤其在财务报告、运营分析和库存管理中。 ...
Read Now →在复杂查询中查询多个数据库时,您如何处理数据差异?
多数据库查询中的数据差异源于不同数据源之间的模式、数据表示、时间(延迟)或数据质量的差异。处理这些差异对于确保查询结果的准确性、报告的可靠性以及在分布式系统、数据集成和跨异构数据存储的商业智能等场景中做出明智决策至关重要。 关键原则包括识别差异来源、定义解决规则和确保一致性。核心方法包括:建立规范...
Read Now →

