

自动化数据管道和工作流将如何改变大数据架构?
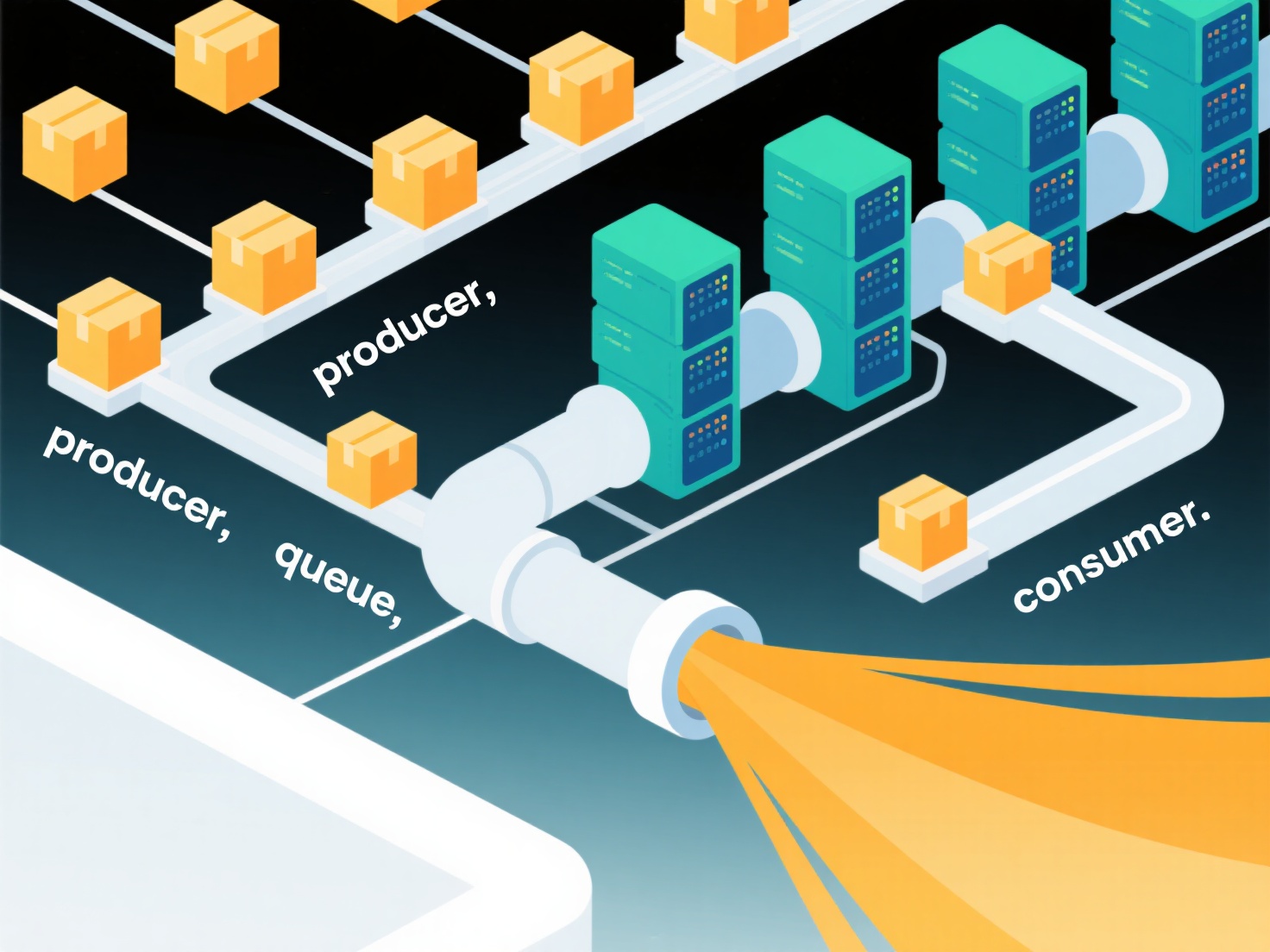
自动化数据管道和工作流是用于摄取、转换和交付数据的编码序列,由事件或调度触发。它们的重要性在于用可靠、可重复的流程取代复杂的手动脚本编写和协调工作。关键应用场景包括实时分析、定期批量报告和机器学习模型部署,在这些场景中,及时、一致的数据流至关重要。它们从根本上改变了大数据架构,实现了事件驱动、弹性且可扩展的数据移动,无需持续的人工监督。
核心特性包括强大的调度、依赖管理、错误处理和监控能力。驱动自动化的原则是编排(如Airflow、Prefect、Dagster等工具)、基础设施抽象和声明式定义。这种自动化通过将重点从复杂的移动逻辑转向数据可靠性和可用性,对架构产生深远影响。架构变得更加精简,将摄取(如Kafka)、处理(Spark、Flink)和存储(数据湖仓、数据仓库)无缝集成到托管工作流中,减少了自定义编码。
自动化带来了运营效率的提升、错误的减少和洞察时间的加速。实施过程包括:选择编排工具、定义管道任务(提取、清理、丰富、加载)、设置触发器/调度、制定错误处理策略以及集成监控。典型场景包括用于仪表板的每日ETL或流点击流处理。业务价值体现在更快的决策制定、因减少人工干预而降低的运营成本,以及为下游分析和AI提供增强的数据可靠性。
继续阅读
你如何管理数据湖以进行高级分析?
数据湖在可扩展存储库(如云对象存储,例如AWS S3、Azure ADLS)中以原生格式(结构化、半结构化、非结构化)存储海量原始数据。它是高级分析(机器学习、预测建模、人工智能)的基础,因为它支持灵活存储和分析各种数据源,无需预先定义架构。关键概念包括摄入层、元数据、访问控制和处理引擎,可实现经济...
Read Now →大数据如何支持深度学习应用?
大数据为有效的深度学习提供了基础燃料。深度学习模型以复杂的神经网络架构为特征,需要海量、多样且通常是非结构化的数据来学习复杂的模式和表示。没有大数据,这些模型就缺乏足够的有意义训练示例,从而严重限制其准确性和泛化能力。其应用范围从图像和语音识别到预测分析和自主系统。 核心原则是深度学习模型的性能随...
Read Now →如何优化大数据架构以提高成本效益?
大数据成本优化可在保持系统性能和可扩展性的同时最大限度地减少基础设施支出。关键概念包括存储分层、存储与计算分离、自动扩展和资源合理配置。随着数据量的增长,这种效率至关重要,尤其是在云环境中,资源的浪费性使用会直接影响运营预算。它支持可持续的分析、机器学习管道和大规模数据处理,且不会产生过高成本。 ...
Read Now →

