

边缘计算在实时应用中部署机器学习模型时的作用是什么?
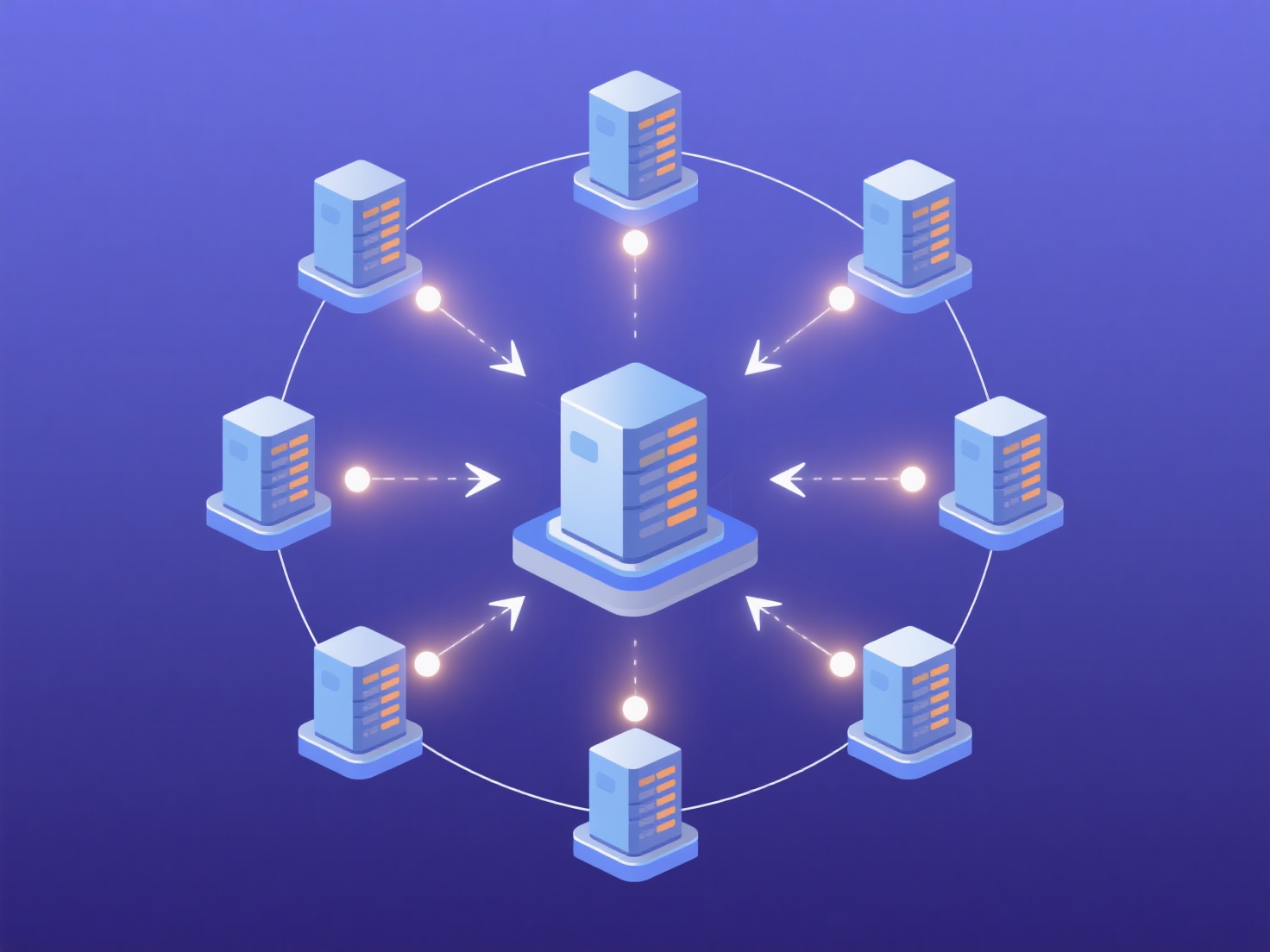
边缘计算在数据源附近处理数据,例如物联网设备或本地服务器,而不是仅仅依赖遥远的云数据中心。它在实时机器学习(ML)模型部署中的作用对于最小化延迟和带宽消耗至关重要。这实现了即时分析和响应。主要应用包括需要即时障碍物检测的自动驾驶汽车、进行实时预测性维护的工业机械,以及持续监测生命体征的医疗可穿戴设备。
核心原则包括将优化的机器学习模型直接部署到边缘设备或附近的网关。这允许进行本地推理,即预测或决策在数据生成的地方进行,消除了往返云端的延迟。它支持离线或间歇性连接场景,通过将敏感信息保留在本地来增强数据隐私,并降低流式传输原始传感器数据的巨大带宽成本。因此,它通过实现实时质量控制改变了工业自动化等领域,并通过促进即时交通流量优化改变了智能城市。
在边缘部署机器学习模型的步骤:1)训练并压缩模型以适应资源受限的设备;2)使用TensorFlow Lite或ONNX Runtime等框架将模型集成到应用程序中;3)通过边缘编排平台进行部署。这带来了显著的业务价值:实现对安全关键系统至关重要的真正实时决策,通过即时AI功能(例如手机上的实时视频对象识别)改善用户体验,并允许在缺乏稳定连接的偏远地区进行分析。
继续阅读
如何使用网格搜索或随机搜索进行超参数优化?
超参数优化旨在为机器学习模型的配置参数(超参数)找到最佳设置。网格搜索和随机搜索可自动执行此过程,这对于在数据库查询预测、异常检测或客户细分等任务中最大化模型性能至关重要。当默认超参数产生次优结果时,就会应用这些方法。 网格搜索会详尽地评估预定义超参数值集合内的每一种组合。它具有系统性,但在超参数...
Read Now →什么是特征工程,它如何改进机器学习模型?
特征工程是利用领域知识从原始数据中创建新的输入变量(特征)或转换现有变量,以提高机器学习模型性能的过程。特征是所观测数据的可测量属性或特征。其重要性在于以更好地向学习算法呈现潜在问题的方式准备数据。这在欺诈检测、推荐系统、医疗诊断和预测性维护等应用中至关重要。 核心组件包括特征创建、特征转换(如归...
Read Now →如何使用大型数据集训练深度学习模型?
使用大型数据集训练深度学习模型需要可扩展的技术来克服内存和计算瓶颈。关键概念包括分布式计算和高效的数据处理。其意义在于使模型能够从海量数据中学习复杂模式,这对于计算机视觉和自然语言处理等领域的最先进性能至关重要。标准的单机设置通常是不够的。 核心方法包括在多个GPU或机器之间分配工作负载。数据并行...
Read Now →

