

什么是数据仓库建模?核心方法与步骤解读
本文发表于: &{ new Date(1750176000000).toLocaleDateString() }
1. 什么是数据仓库建模?
数据仓库建模是指根据业务需求和分析目标,设计和组织数据仓库中数据结构的过程。它将原始数据转化为易于理解且优化的格式,以支持高效的数据存储、检索和分析。与传统数据库建模不同,数据仓库建模专注于分析场景,旨在提供一个集成的、面向主题的、随时间变化的数据视图,为决策支持提供基础。
数据仓库建模的本质是为分析场景设计最优数据结构,使复杂的业务数据能够被高效地查询和分析。数据仓库建模是连接原始数据与业务洞察的桥梁,它决定了企业数据分析的效率与深度。
2. 数据仓库建模的3种主流方法
特性 | 星型模型 | 雪花模型 | 星座模型 |
查询效率 | 高 | 中 | 中-高 |
存储成本 | 高(有冗余) | 低 | 中 |
维护难度 | 低 | 高 | 中-高 |
灵活性 | 中 | 高 | 高 |
实现复杂度 | 低 | 高 | 中-高 |
2.1 星型模型(Star Schema)
星型模型是数据仓库建模中最常用的模式之一,因其结构类似星星而得名。它由一个中心事实表和多个维度表组成,事实表包含业务度量值,而维度表则包含描述性属性。
.PNG)
核心特点:
- 事实表存储可度量的业务事件数据(如销售额、数量)
- 维度表存储描述性信息(如产品、客户、时间)
- 事实表通过外键与各维度表相连
- 结构简单,易于理解和查询
适用场景:
- 简单查询和快速分析场景
- 报表和仪表盘开发
- 需要高性能查询响应的应用
StarRocks的列式存储和MPP架构特别适合星型模型,能够高效处理多表关联查询。其向量化执行引擎可以显著提升星型模型中常见的聚合和过滤操作性能。
星型模型以其简洁的结构和优异的查询性能,成为数据仓库建模的首选方案,特别适合需要快速响应的分析场景。
2.2 雪花模型(Snowflake Schema)
雪花模型是星型模型的扩展变体,它对维度表进行了规范化处理,形成了多层级的维度结构。

核心特点:
- 维度表被进一步规范化,减少数据冗余
- 形成层次化的维度结构
- 支持更复杂的维度层级关系
- 存储空间效率更高
适用场景:
- 复杂业务层级与高数据规范性要求
- 维度数据频繁变化的环境
- 数据完整性和一致性要求高的场景
雪花模型通过规范化维度表减少了数据冗余,提高了数据一致性,但代价是增加了查询复杂度和可能影响查询性能,适合那些数据规范性需求高于查询性能的场景。
2.3 星座模型(Galaxy Schema)
星座模型(也称为事实星座模型)是多个星型模型的集合,它们共享一些公共维度表。
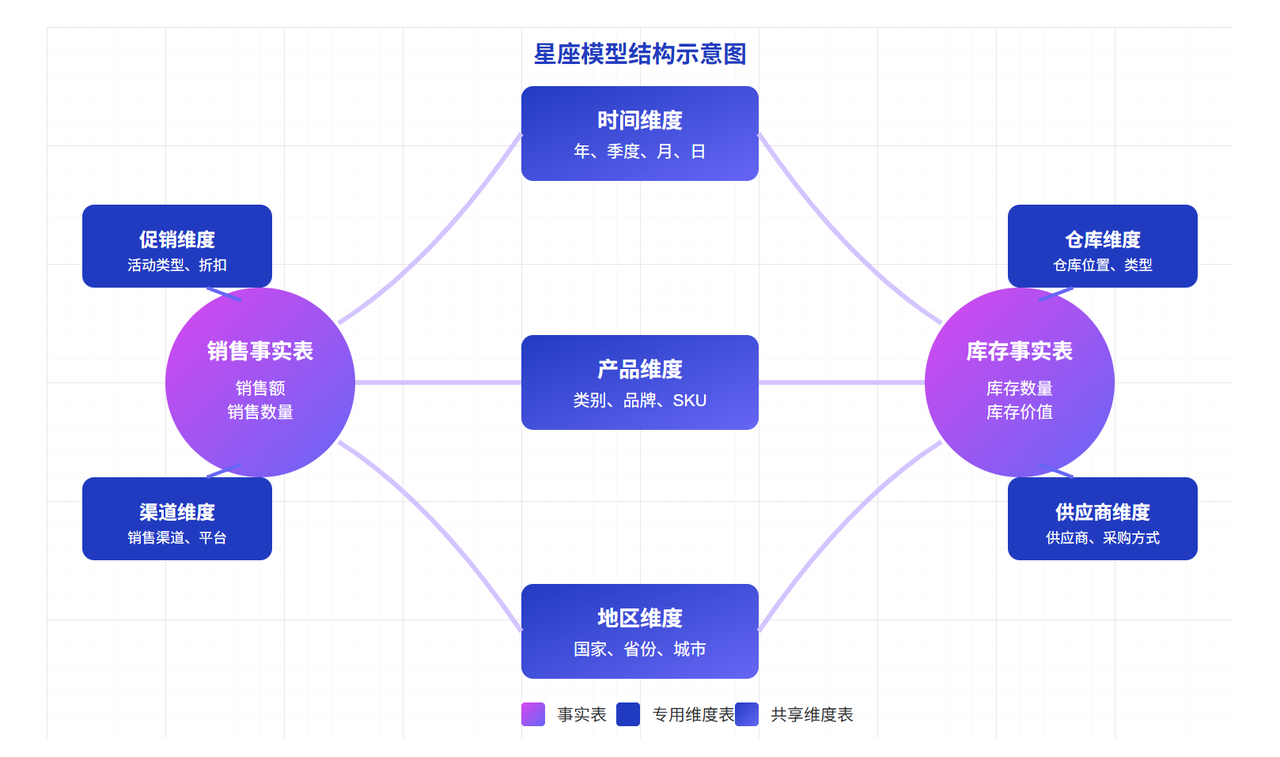
核心特点:
- 包含多个事实表
- 事实表之间共享维度表
- 支持跨业务领域的综合分析
- 适合企业级数据仓库
适用场景:
- 大型企业级数据中台
- 需要跨部门、跨业务线分析的场景
- 复杂的企业数据集成需求
星座模型通过共享维度实现了多业务领域的数据整合,为企业提供了全面的分析视角,是大型组织构建统一数据视图的理想选择。
3. 数据仓库建模的5个关键步骤
步骤1:需求分析
数据仓库建模的第一步是深入理解业务需求和分析目标。这包括:
- 识别关键业务问题和决策点
- 确定需要回答的分析问题(如销售趋势、客户行为、运营效率)
- 明确报表和分析的粒度要求
- 确定数据更新频率和历史数据需求
- 识别关键利益相关者和最终用户
有效的需求分析应该产出明确的业务指标定义、数据字典和分析用例文档。需求分析是数据仓库建模的基石,它确保了技术实现与业务目标的一致性,避免了"为技术而技术"的陷阱。
步骤2:选择建模方法
基于需求分析的结果,选择适合的建模方法:
- 对于简单报表和快速分析,星型模型通常是最佳选择
- 当维度数据复杂且需要严格规范化时,雪花模型更为适合
- 对于需要整合多个业务领域的企业级数据仓库,星座模型是理想选择
选择时需考虑因素:
- 数据复杂度和业务关系
- 查询性能要求
- 维护成本和团队技能
- 未来扩展性需求
建模方法的选择不是一成不变的,而是应根据具体业务场景和技术环境灵活决定,最佳的建模方法是能够平衡业务需求与技术实现的方法。
步骤3:设计事实表与维度表
事实表设计原则:
- 确定业务过程和粒度(如每日销售、每笔交易)
- 识别关键度量指标(如销售额、数量、成本)
- 确定事实表类型(事务型、周期快照型或累积快照型)
- 设计主键策略(通常是维度外键的组合)
- 考虑聚合策略和预计算
维度表设计原则:
- 包含丰富的描述性属性,支持多角度分析
- 设计维度层级(如产品类别-子类别-产品)
- 处理缓慢变化维度(SCD)策略
- 考虑退化维度和角色扮演维度
- 确保维度属性的一致性和完整性
良好的事实表和维度表设计是数据仓库性能和可用性的关键,它们共同构成了分析模型的骨架,决定了数据仓库能够回答哪些业务问题以及回答的效率。
步骤4:ETL与数据加载
设计完数据模型后,需要实现数据的提取、转换和加载(ETL)流程:
- 数据源识别与连接设计
- 数据清洗和质量控制规则
- 转换逻辑和业务规则实现
- 增量加载策略
- 错误处理和恢复机制
- 数据加载调度和监控
在StarRocks环境中,可以利用其高性能导入功能和多种导入方式(如Broker Load、Stream Load等)实现高效的数据加载。StarRocks的实时导入能力特别适合需要近实时数据分析的场景。
步骤5:模型验证与迭代
数据仓库建模是一个迭代过程,需要持续验证和优化:
- 执行性能测试和查询优化
- 验证数据一致性和完整性
- 收集用户反馈并调整模型
- 监控查询模式和性能瓶颈
- 根据业务变化调整模型
利用StarRocks的监控工具和查询分析功能,可以识别性能瓶颈并进行针对性优化,如调整分区策略、优化索引设计或调整物化视图。
数据仓库建模不是一次性工作,而是一个持续优化的过程,只有通过不断迭代,才能确保数据模型始终满足业务需求并保持最佳性能。
结语
数据仓库建模是连接原始数据与业务洞察的关键环节,它决定了企业能否从海量数据中提取有价值的信息。
StarRocks凭借其卓越的性能、灵活的架构和丰富的功能,为数据仓库建模提供了强大支持,帮助企业克服传统数据仓库面临的挑战,实现从数据到洞察的快速转化。无论是构建新的数据仓库,还是优化现有系统,StarRocks都能提供显著的价值,助力企业在数据驱动的时代保持竞争优势。
在数据量持续增长、分析需求不断复杂化的今天,选择正确的数据仓库建模方法和技术平台比以往任何时候都更为重要。StarRocks作为新一代高性能分析数据库,正成为越来越多数据密集型企业的首选解决方案。


