

Hadoop 分布式文件系统(HDFS)详解
本文发表于: &{ new Date(1754668800000).toLocaleDateString() }
HDFS 基础:大数据时代的基础
Hadoop 分布式文件系统(HDFS)是 Apache Hadoop 生态系统的核心组件,专为运行在商用硬件集群上而设计。作为大数据处理的基础设施,HDFS 在过去十多年来一直是企业存储和处理海量数据的首选解决方案。
HDFS 的核心设计理念
HDFS 的设计初衷是为了满足以下几个关键需求:
- 处理超大文件:HDFS 适合存储大小为 GB 到 TB 级别的文件,能够支持数百万个文件的单个实例。
- 流式数据访问:HDFS 设计理念是"一次写入,多次读取",强调数据吞吐量而非低延迟访问。
- 容错性:HDFS 通过数据复制机制提供高容错性,默认每个数据块复制三份,分布在不同服务器上。
- 简单一致性模型:HDFS 提供"写入一次,读取多次"的文件访问语义,一旦创建并关闭,文件内容不会改变。
- 可移植性:HDFS 可在各种异构硬件和软件平台上运行。

HDFS 的架构组成
HDFS 采用主从(Master/Slave)架构,由以下主要组件构成:
1. NameNode(主节点):
- 管理文件系统命名空间
- 记录文件与数据块之间的映射关系
- 控制客户端对文件的访问
- 管理数据块的复制策略
2. DataNode(数据节点):
- 存储实际的数据块
- 执行数据块的创建、删除和复制
- 向 NameNode 报告所存储的块列表
- 定期发送心跳信息确认工作状态
3. Secondary NameNode:
- 定期合并 NameNode 的编辑日志
- 减轻 NameNode 的负担
- 非热备份,不能直接替代 NameNode
.PNG)
HDFS 的工作原理
HDFS 的工作流程可以概括为以下几个关键步骤:
1. 文件存储:
- 文件被分割成固定大小的数据块(默认 128MB)
- 数据块被复制到多个 DataNode 上(默认 3 个副本)
- NameNode 记录每个文件的块位置信息
2. 数据读取:
- 客户端向 NameNode 请求文件块位置
- NameNode 返回包含数据块的 DataNode 列表
- 客户端直接从 DataNode 读取数据,绕过 NameNode
3. 数据写入:
- 客户端首先通知 NameNode 创建文件
- NameNode 分配数据块并确定存储位置
- 客户端直接向第一个 DataNode 写入数据
- 数据以管道方式在 DataNode 之间复制
HDFS 的这种设计使其非常适合批处理工作负载,但对于实时分析场景存在一定局限性。
HDFS 的优势与局限:大数据时代的挑战
HDFS 的显著优势
HDFS 作为大数据存储基础设施,具有以下显著优势:
- 高可靠性:通过数据块复制机制,HDFS 能够在硬件故障情况下保持数据完整性。
- 高扩展性:可以通过简单添加商用服务器来扩展存储容量。
- 成本效益:支持在普通硬件上运行,降低了存储大数据的成本。
- 适合批处理:专为高吞吐量数据访问而优化,非常适合 MapReduce 等批处理框架。
- 开源生态:与 Hadoop 生态系统的其他组件无缝集成。
然而,随着企业数据分析需求的演变,传统 HDFS 架构的局限性日益凸显。
HDFS 在现代分析场景中的局限
随着企业对实时数据分析需求的增长,HDFS 的以下局限性变得越来越明显:
1. 不适合小文件存储:
- NameNode 将文件系统元数据存储在内存中
- 大量小文件会消耗大量内存资源
- 访问小文件的开销与文件大小不成比例
2. 不支持文件随机修改:
- 仅支持追加写入,不支持随机位置修改
- 数据更新需要重写整个文件
3. 高延迟:
- 设计偏向高吞吐量而非低延迟
- 启动作业有固定开销,不适合交互式查询
4. 分析性能瓶颈:
- 与计算层分离,数据需要在网络间传输
- 缺乏现代列式存储和向量化执行技术
- 无法满足亚秒级查询响应需求
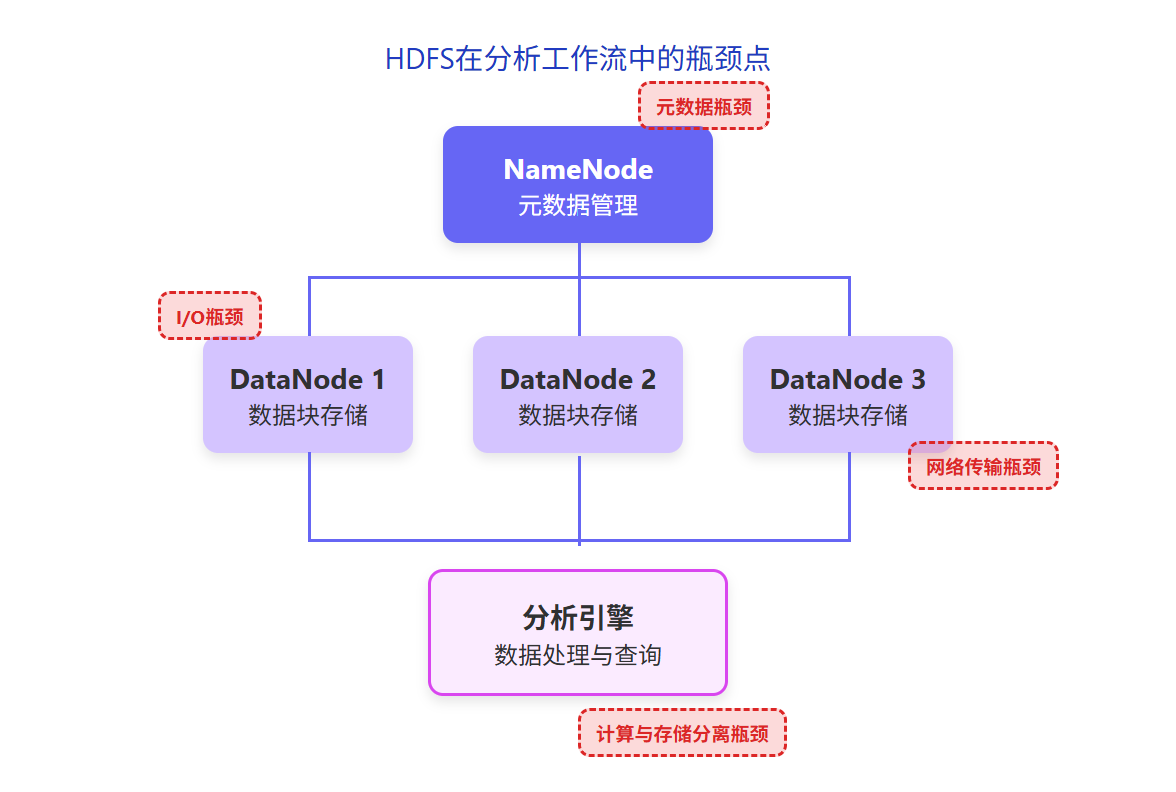
数据分析领域的演进需求
企业数据分析需求正在从传统的批处理向实时分析转变:
- 实时洞察:业务决策需要基于最新数据,要求分析系统能够处理流式数据并提供实时结果。
- 交互式查询:用户期望能够以亚秒级的响应时间进行探索性分析。
- 统一数据平台:需要一个平台同时处理批处理、交互式查询和实时分析。
- 降低复杂性:减少数据在不同系统间移动,简化架构。
- 成本优化:提高硬件资源利用率,降低总体拥有成本。
这些需求推动了数据处理架构从传统的 Hadoop 批处理向现代湖仓一体化架构的演进。
从 HDFS 到湖仓一体:数据架构的现代化之路
大数据架构的演进历程
大数据处理架构经历了几个关键发展阶段:
1. 第一代:Hadoop 批处理时代
- 以 HDFS 为存储基础
- 依赖 MapReduce 进行批处理
- 处理时间以小时或天计算
2. 第二代:数据仓库和数据湖并行
- 数据湖:存储原始数据,基于 HDFS 构建
- 数据仓库:用于高性能分析查询
- 数据在两个系统间复制,导致数据冗余和一致性问题
3. 第三代:湖仓一体化(Lakehouse)
- 结合数据湖的灵活性和数据仓库的性能
- 支持直接在数据湖上进行高性能分析
- 消除了数据移动和转换的复杂性
开放数据湖格式的兴起
为了解决 HDFS 的局限性,同时保留其优势,开放数据湖格式应运而生:
1. Apache Iceberg:
- 提供表格式抽象层
- 支持 ACID 事务
- 允许表结构演进
- 实现快照隔离
2. Apache Hudi:
- 提供记录级更新和删除
- 支持增量处理
- 提供近实时数据摄取能力
3. Delta Lake:
- 提供事务日志
- 支持数据版本控制
- 实现模式强制执行
4. Apache Paimon:
- 新一代流式数据湖格式
- 为实时分析场景优化
- 支持高效的流批一体处理
这些开放格式解决了 HDFS 的部分局限性,但仍然需要高性能的查询引擎来释放数据价值。
湖仓一体架构的核心优势
湖仓一体架构为企业带来了以下核心优势:
- 降低数据复制:数据只需存储一次,减少存储成本和数据不一致风险。
- 简化架构:减少系统数量,降低维护复杂性。
- 统一数据访问:提供一致的数据访问层,简化应用开发。
- 增强数据治理:集中式管理提高数据质量和合规性。
- 灵活性与性能兼备:保留数据湖的灵活性,同时提供数据仓库级别的性能。
然而,实现真正的湖仓一体架构需要一个能够直接高效查询数据湖的引擎。这就是 StarRocks 的核心价值所在。
StarRocks:重定义数据分析的现代方案
StarRocks 提供了多种方式与 HDFS 及基于 HDFS 构建的数据湖进行集成:
1. External Catalog:
2. 数据湖分析引擎:
- 针对数据湖格式优化的查询执行
- 支持谓词下推和动态过滤
- 智能分区裁剪
3. 数据缓存机制:
- 自动缓存热点数据
- 大幅减少 I/O 开销
- 支持缓存预热
以下是创建外部目录连接 HDFS 上数据的示例:
-- 创建连接Iceberg数据的外部目录
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://metastore-host:9083"
);
-- 创建连接Hudi数据的外部目录
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://metastore-host:9083"
);
-- 创建连接Delta Lake数据的外部目录
CREATE EXTERNAL CATALOG deltalake_catalog_hms
PROPERTIES(
"type" = "deltalake",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://metastore-host:9083"
);通过这些集成能力,StarRocks 实现了对 HDFS 数据的极速分析,同时保留了 HDFS 的数据管理优势。
物化视图:HDFS 数据分析的加速器
StarRocks 的物化视图功能为 HDFS 数据分析提供了显著的性能提升:
1. 异步预聚合:
- 预先计算常用聚合结果
- 大幅减少查询时计算量
- 支持复杂的多表 JOIN 场景
2. 智能查询改写:
- 自动识别可使用的物化视图
- 透明重写查询以利用预计算结果
- 无需应用修改
3. 增量更新机制:
- 仅处理变化的数据
- 降低维护开销
- 保证数据一致性
对于 HDFS 上的数据,物化视图可以将查询性能提升 10 倍以上,同时减轻原始数据存储系统的负担。
企业实践:从 HDFS 到 StarRocks 的成功转型案例
案例一:小红书湖仓架构的跃迁之路
小红书面临的挑战:
- 数据规模快速增长,传统 HDFS+Hive 架构性能瓶颈明显
- 用户对实时数据洞察的需求与日俱增
- 多种数据源管理复杂度高
StarRocks 解决方案:
- 构建湖仓一体化架构,直接分析 HDFS 上的数据
- 利用物化视图加速常见分析路径
- 统一批处理和实时分析平台
实施成果:
- 查询性能提升 10 倍以上
- 实现了亚秒级的交互式分析体验
- 简化了数据架构,降低了维护成本
案例二:58 同城从 Spark 到 StarRocks 的湖仓转型
58 同城面临的挑战:
- 基于 HDFS 的传统批处理系统无法满足实时分析需求
- 复杂数据管道导致延迟高、维护成本大
- 数据一致性难以保证
StarRocks 解决方案:
- 采用 StarRocks 直接查询 HDFS 上的数据
- 实现批处理和实时处理的统一
- 简化数据流程,消除中间环节
实施成果:
- 查询延迟从分钟级降至秒级
- 数据新鲜度显著提升
- 总体拥有成本降低 40%
案例三:腾讯游戏利用 StarRocks 统一游戏分析
腾讯游戏面临的挑战:
- 游戏数据规模庞大,存储在 HDFS 集群中
- 分析场景复杂,从简单报表到复杂用户行为分析
- 传统解决方案难以平衡性能和成本
StarRocks 解决方案:
- 建立统一的分析平台,直接连接 HDFS 数据
- 利用物化视图优化常见查询路径
- 实现 AI+湖仓一体的创新架构
实施成果:
- 支持上万并发查询,性能提升 5 倍以上
- 实现了毫秒级的实时数据洞察
- 数据分析能力从 BI 报表扩展到 AI 驱动的决策支持
HDFS 数据迁移到 StarRocks 的最佳实践
数据迁移策略
从 HDFS 迁移到 StarRocks 有多种策略可供选择:
1. 直接查询模式:
- 保留数据在 HDFS,使用 StarRocks 外部目录直接查询
- 优点:无需数据迁移,实施简单
- 适用场景:数据量大,迁移成本高,查询频率适中
2. 全量导入模式:
- 将 HDFS 数据完全导入 StarRocks 内部表
- 优点:最佳查询性能,完全控制
- 适用场景:高频查询,性能要求极高
3. 混合模式:
- 热数据导入 StarRocks 内部表,冷数据保留在 HDFS
- 优点:平衡性能和成本
- 适用场景:数据温度差异明显
数据导入技术
StarRocks 提供多种工具从 HDFS 导入数据:
1. Spark-StarRocks Connector:
- 利用 Spark 并行处理能力
- 支持大规模数据迁移
- 适合初始数据加载
2. Flink-StarRocks Connector:
- 支持流式和批量数据导入
- 实现近实时数据同步
- 适合增量数据更新
3. INSERT INTO SELECT:
- 直接从外部表查询并插入内部表
- 简单易用,无需额外工具
- 适合中小规模数据
-- 使用INSERT INTO SELECT从HDFS数据导入StarRocks
INSERT INTO internal_table
SELECT * FROM iceberg_catalog.db.table
WHERE create_time > '2024-01-01';性能优化建议
从 HDFS 迁移到 StarRocks 后,可采取以下措施优化性能:
1. 表设计优化:
- 合理设计分区和分桶策略
- 选择适当的数据类型和编码
- 利用主键模型进行实时更新
2. 物化视图加速:
- 为热点查询路径创建物化视图
- 针对聚合查询进行预计算
- 定期监控和调整视图性能
3. 查询优化:
- 利用 Query Profile 分析查询瓶颈
- 优化 JOIN 策略和顺序
- 合理设置并行度和资源限制
4. 资源管理:
通过这些最佳实践,企业可以顺利完成从 HDFS 到 StarRocks 的迁移,充分发挥数据价值。
HDFS 与现代数据分析的融合趋势
企业数据战略建议
面对 HDFS 和现代数据分析的融合趋势,企业应考虑以下战略调整:
1. 评估现有 HDFS 投资:
- 盘点当前 HDFS 数据资产
- 识别性能瓶颈和业务痛点
- 确定现代化优先级
2. 采用渐进式迁移策略:
- 从高价值分析场景开始
- 利用 StarRocks 直接查询能力降低迁移风险
- 逐步实现架构现代化
3. 建立统一数据平台:
- 整合批处理和实时分析能力
- 统一元数据管理
- 简化数据流程
4. 培养新技能:
- 投资团队湖仓一体化技能培养
- 构建数据产品思维
- 关注实时分析最佳实践
通过这些战略调整,企业可以在保护现有 HDFS 投资的同时,实现数据分析能力的现代化升级。
结论:从 HDFS 到 StarRocks 的演进之路
Hadoop 分布式文件系统(HDFS)作为大数据时代的奠基石,为企业处理海量数据提供了坚实基础。然而,随着数据分析需求向实时化、交互式发展,传统 HDFS 架构的局限性日益凸显。
现代企业需要的不仅是可靠的数据存储,更是能够从数据中快速获取洞察的分析能力。StarRocks 通过创新的技术架构,成功实现了对 HDFS 数据的极速分析,帮助企业完成从批处理到实时分析的技术飞跃。
湖仓一体化架构正在成为数据处理的新范式,它结合了数据湖的灵活性和数据仓库的性能优势。StarRocks 作为领先的分析引擎,为企业提供了实现这一架构的关键能力。
通过本文介绍的最佳实践和成功案例,企业可以制定适合自身情况的 HDFS 现代化路径,充分释放数据价值,在数字化转型的道路上取得领先优势。
本文由镜舟科技技术团队撰写,基于 StarRocks 实际生产环境的应用经验总结而成。如需了解更多关于 StarRocks 如何帮助企业实现数据分析现代化,请访问业务咨询。


