

如何使用索引来优化涉及WHERE子句的查询?
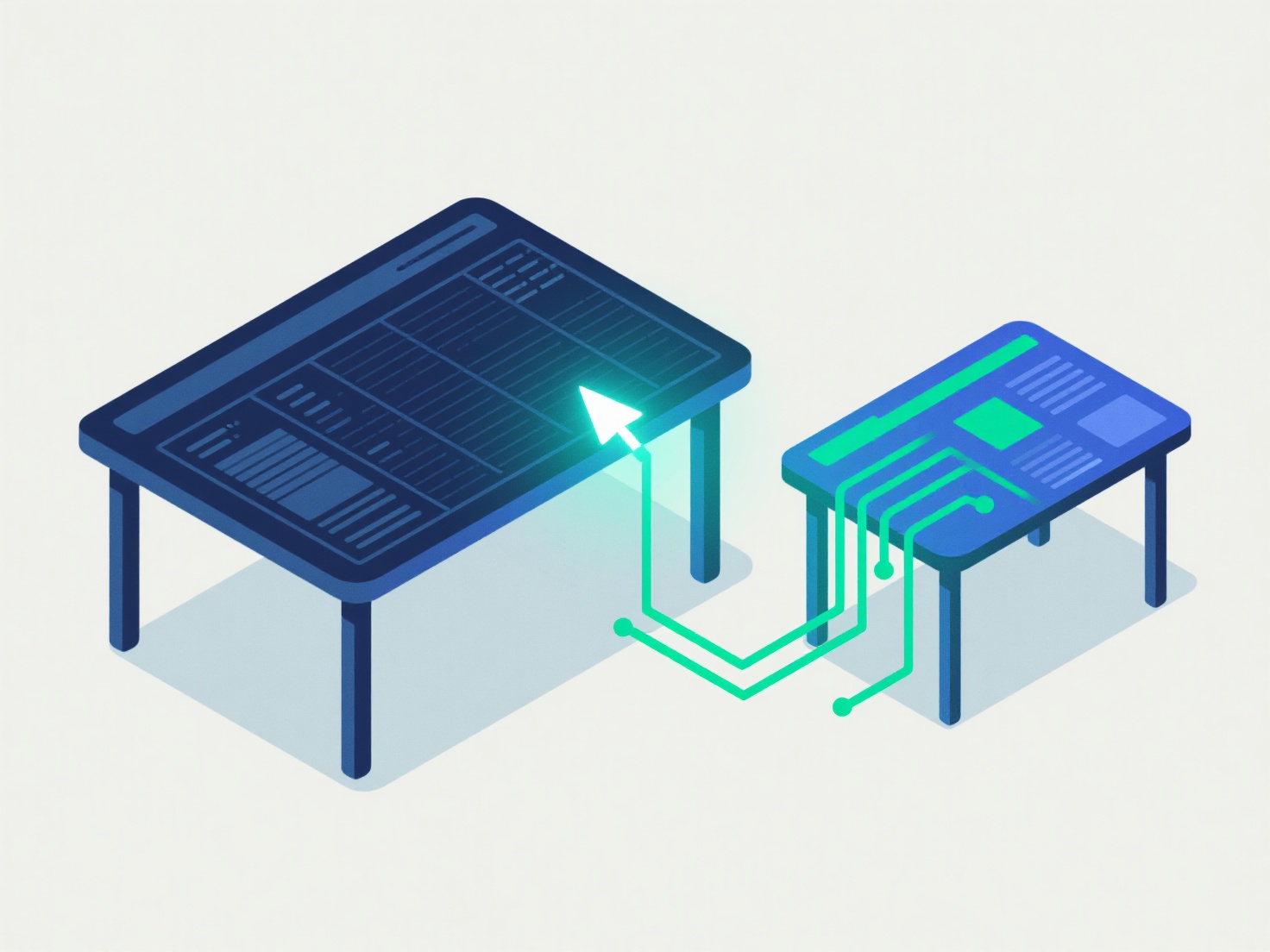
索引通过允许数据库比全表扫描更高效地定位特定行,显著提升了WHERE子句的查询性能。索引就像一个排序列表,通常结构化为B树,存储选定列值的副本以及指向主表中对应行的指针。这在涉及频繁搜索、筛选或基于特定列连接的场景中至关重要,尤其是在大型数据集上。使用`=`、`>`、`<`、`BETWEEN`和`IN`等运算符的查询受益最大。
有效的索引取决于选择性。为WHERE子句中经常使用的高选择性列(如唯一ID)创建索引,这些列的筛选条件会排除大部分行。复合索引可以进一步优化多列筛选的查询;定义索引顺序以匹配查询的筛选条件。索引支持索引查找和仅索引扫描等操作,大幅减少I/O。然而,它们会给INSERT、UPDATE和DELETE操作带来开销,因为必须维护索引结构。精心创建和维护索引对整体系统性能至关重要。
实施优化的步骤:1) 使用性能监控工具识别慢查询。2) 分析它们的WHERE子句和JOIN条件。3) 为这些条件中频繁使用的列创建索引,优先考虑高基数列。对于多列条件,创建匹配查询谓词的复合索引。4) 使用执行计划验证索引使用情况(PostgreSQL/MySQL中使用`EXPLAIN`,SQL Server中使用`SET SHOWPLAN_TEXT ON`)。5) 避免为极低基数列和未使用的列创建索引。定期审查索引使用情况并删除冗余索引,以最小化写入开销。
继续阅读
如何在多云数据库设置中优化查询?
在多云数据库设置中优化查询可最大限度地减少延迟和成本,这一点至关重要,因为数据分布在AWS、Google Cloud或Azure等提供商之间。关键概念包括了解云之间的网络跃点和数据局部性。有效的优化对于维持应用程序性能和管理跨云边界传输数据所固有的出口费用至关重要。 核心原则包括最大限度地减少跨云...
Read Now →查询优化如何支持大数据分析平台?
查询优化通过识别在海量数据集上执行复杂查询的最高效方法,增强了大数据分析平台的性能。其重要性在于将缓慢且资源密集型的操作转变为可行的流程,从而实现及时的洞察和交互式分析,否则由于数据量过大,这些分析将无法进行。这对于实时客户行为分析、欺诈检测、科学研究和大规模商业智能等应用至关重要,在这些应用中,响...
Read Now →如何优化同时包含OLAP和OLTP操作的查询?
混合OLAP/OLTP查询优化针对的是既需要事务效率又需要复杂分析的工作负载。OLTP优先考虑快速写入/更新和小型索引读取,而OLAP则专注于大规模聚合和扫描。将两者结合给传统的单一用途系统带来了挑战。其重要性体现在实时分析仪表板或直接影响业务决策的运营报告中。实现高性能的混合查询能够在不影响运营系...
Read Now →

